Insurance Analytics
Automating the Ingestion of Spatial Risk Data into Data Warehouses
Contents
Introduction
In today’s data driven world, insurance companies are always seeking out new ways to enhance their decision making process and gain a competitive advantage. With the increased rate of natural catastrophes though, it’s not even a case of gaining competitive advantage anymore (unless you consider the survival of your company to be a competitive advantage!). Insured losses stemming from natural catastrophes have already risen to $50 billion in the first half of 2023, another all-time-high in recent times.
It is imperative that the insurance industry finds a way to manage the risk around these upheavals. This means accounting for these risks so you are not caught off guard. In an earlier blog we already talked about the impact of unmodeled losses on the insurance industry. The repercussions of over- or underexposure to risk by insurance companies also has a tendency to cascade on the global economy, thus leading to a systemic failure. To ensure we don’t get blindsided and find ourselves in a scenario like this, spatial risk data, including climate risk data, needs to seamlessly find its way into the risk modeling framework of insurance companies.
In this article, we do not want to make a case for the importance of spatial risk data to insurance operations. We’re proceeding with the assumption that the reader is already well aware of the wide array of benefits that it provides. You can check out this article if this starting-off-point does not make sense to you yet.
This article focuses on the need to automate the ingestion of spatial risk data into existing data warehouses, how this can be achieved and the potential benefits this offers to insurance companies.
What is the Problem with Manual Data Ingestion?
What better way to showcase the need for the automation of spatial data ingestion than highlighting the challenges associated with the current manual process?
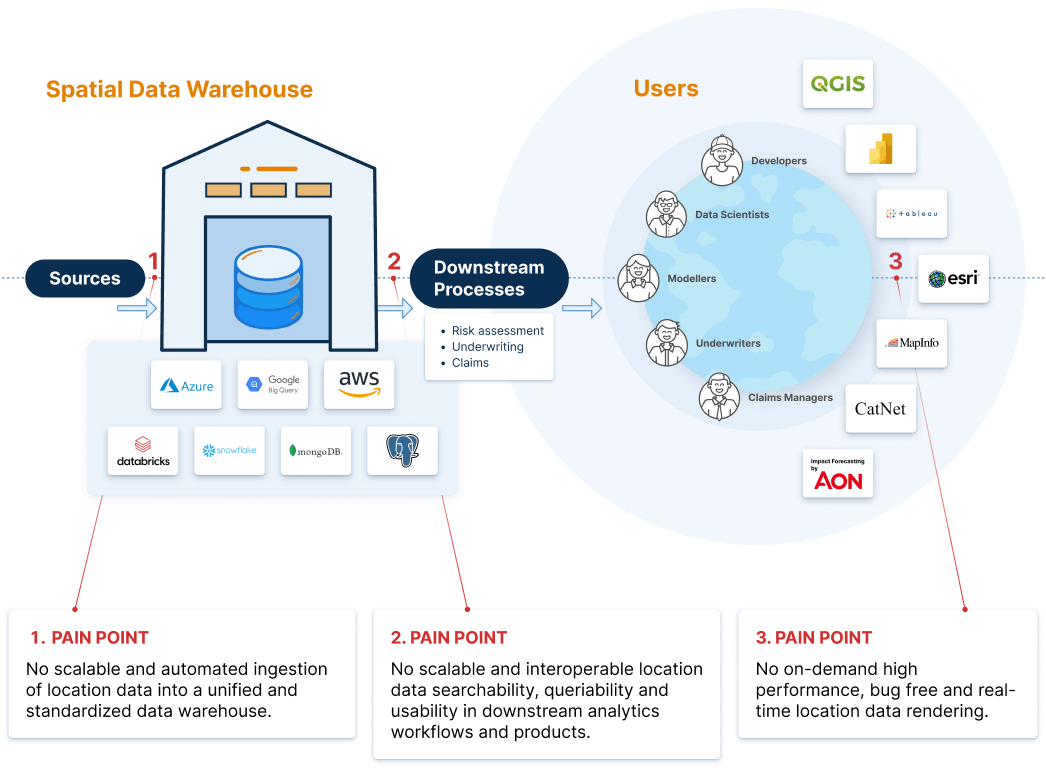
Climate modeling teams within insurance companies receive large amounts of spatial data from countless data vendors and (open) sources as input for their climate models. Spatial data providers offer their data in various proprietary standards, formats and files. This forces climate modeling teams to waste 30% or more of their time and resources on manual data ingestion and structuring activities (parsing, tiling, indexing, unifying, standardizing etc.) in order to be able to use this data effectively for climate modeling and risk assessment. Data analysts and scientists spend their time in cumbersome data wrangling work rather than on insightful data analysis.
Here’s a comprehensive quantification of the issue outlined above based on in-depth talks with leading insurance firms -
- On operational workforce alone, insurance companies are spending somewhere between $1.7M to $5.3M too much on spatial data management annually (representing 10 to 35 FTE doing in-house data management grunt work)
- Third party data deployment and system integration services ($0.5M to $2M)
- Unintended under-exposure to risk creates opportunity cost in the current insurance gap
- Unintended over-exposure to risk easily adds a 10X multitude to this tally
In a nutshell, it is very expensive and time consuming to collect, clean and transform incoming spatial risk data. You can’t really blame decision makers for opting out of the use of these data altogether. But is that really a viable solution? Or just another attempt to kick the can further down the road?
Now that we’ve taken an honest look at the problem at hand, let’s shift our attention to the solution and turn this into an opportunity!
How can Ingestion of Spatial Data into Data Warehouses be Automated?
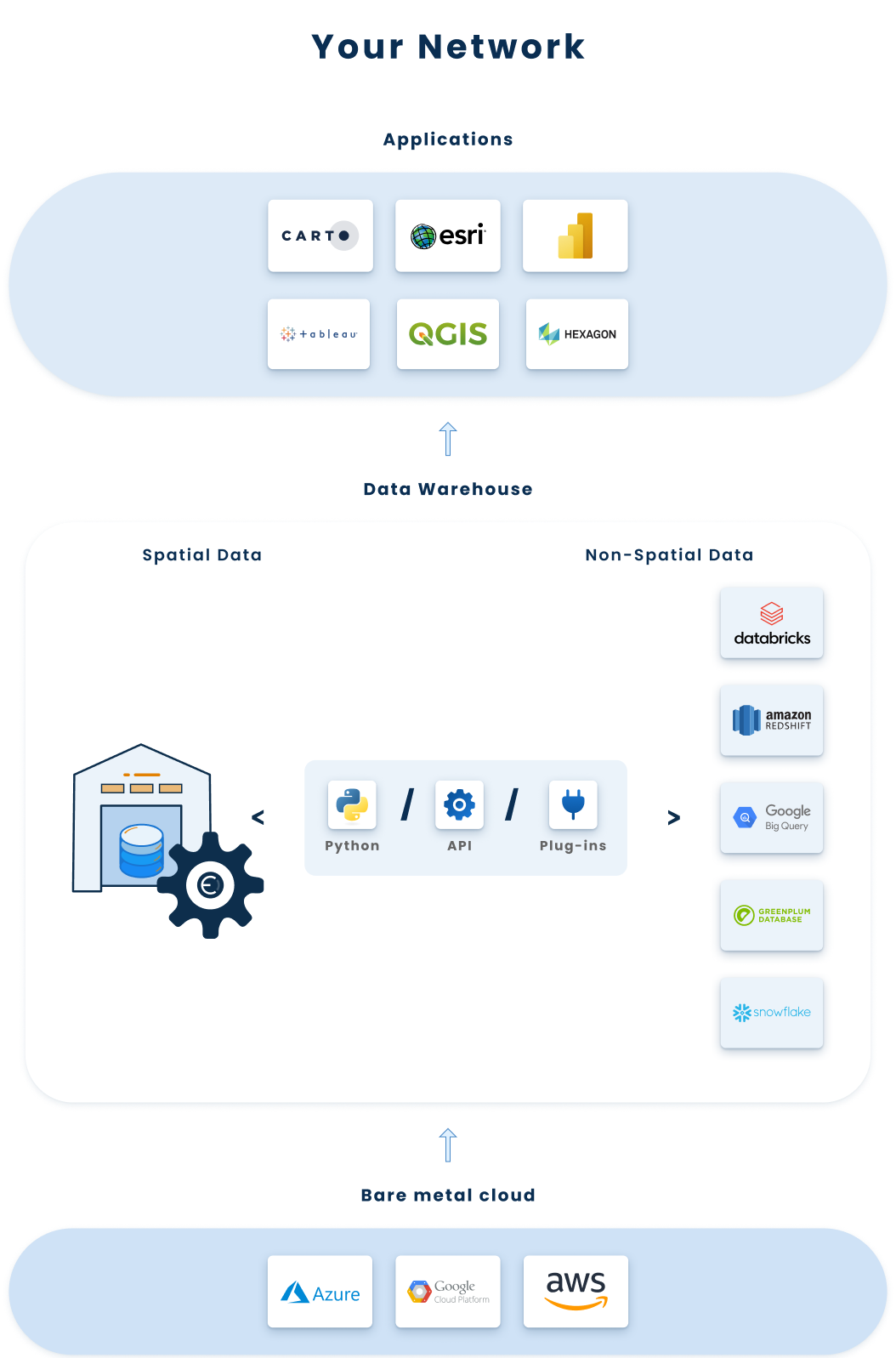
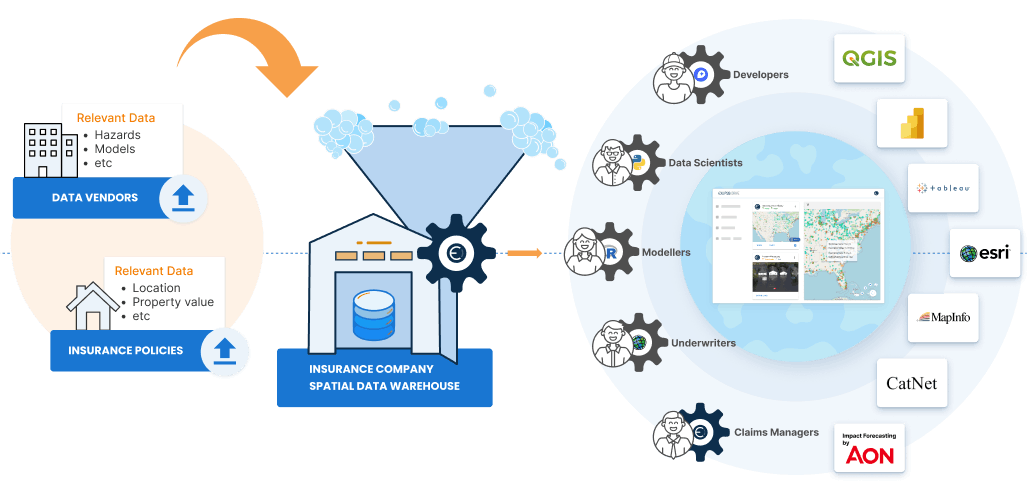
You can automate the manual process of spatial data ingestion, structuring and management by outfitting your company’s existing spatial data warehouses with Ellipsis Drive’s spatial data management infrastructure. This facilitates the standardization, unification, tiling and indexing of insurance exposure data (catastrophe risk data, property characteristics, loss data etc.) and reinsurance data (which may come from other internal sources, vendors, insurers, brokers or other open sources).
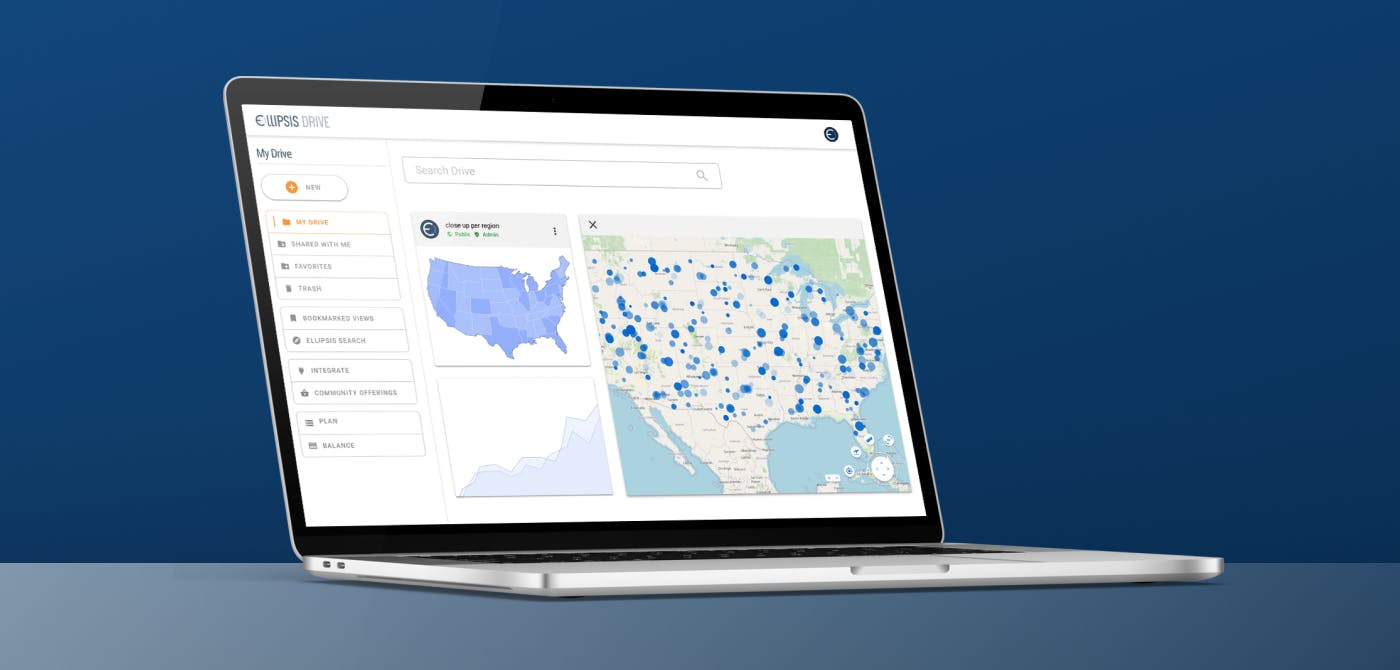
You can launch Ellipsis Drive (ED) on top of an existing bucket, server or warehouse. On launch, your files will be added to the Ellipsis Drive index and ED starts to act as your bucket manager. This way, you can take advantage of the full functionality of ED without the need of data migration.
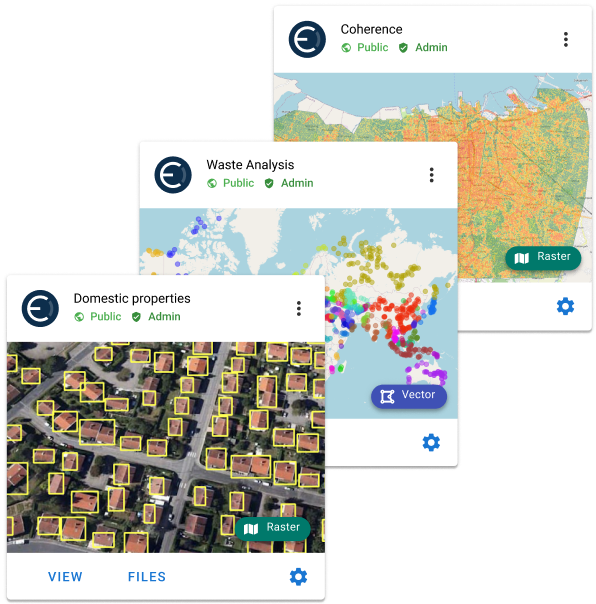
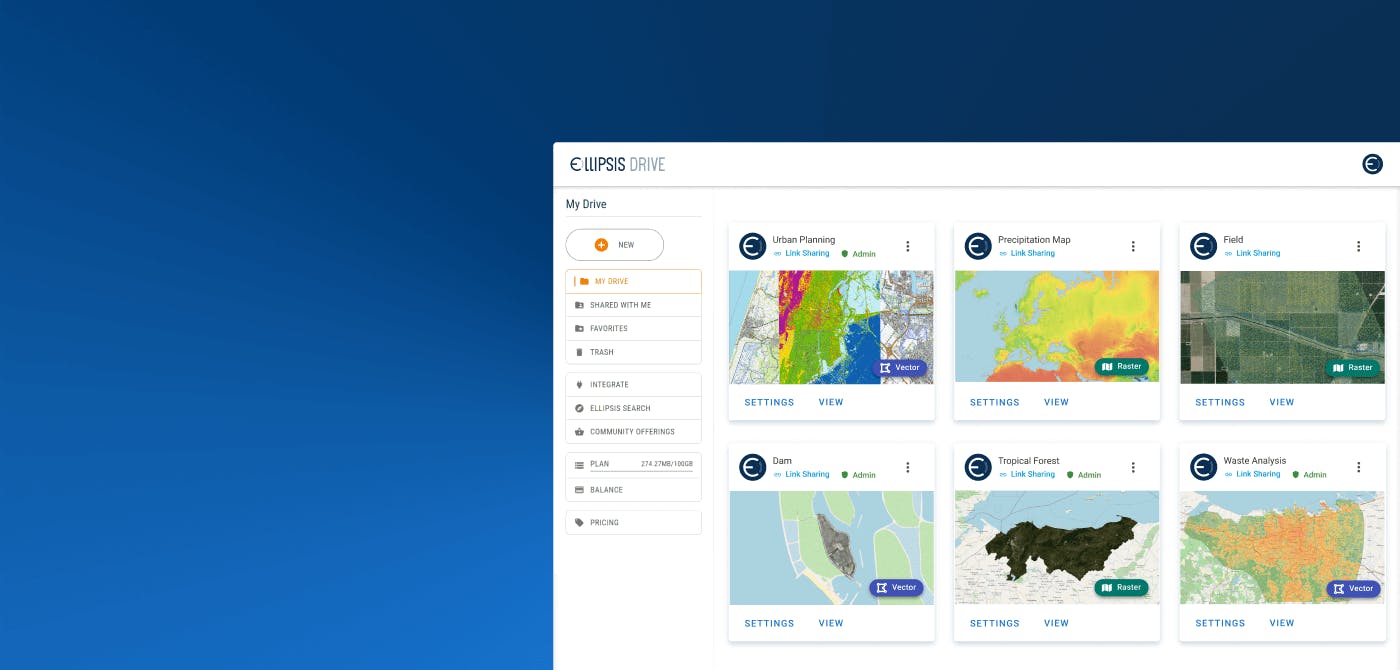
The result of this is that all spatial data (regardless of type, format and volume) are made available on a drag/drop or simple command line basis for high performance and interoperable use by modelers, data scientists, engineers and analysts via Python, R, API, GIS software and Power BI. The image below captures this.
What are the Benefits of Automatic Ingestion of Spatial Risk Data?
As a decision maker, what you’re truly interested in is how the above solution translates into tangible outcomes that positively impact the way in which you conduct your business. Below is a summary of the tried-and-tested impacts of the above described automation solution on a business’ operations -
- Cost & Time Efficiency: 30%+ time saved by streamlining manual spatial data ingestion, structuring and management throughout the entirety of the climate risk modeling workflows
- Data Processing: 8X faster data querying through high performance spatial data use for climate modelers, developers and data scientists directly from their existing workflows
- Real-Time Data Access: 25% faster modeling due to real-time, high performance spatial data access directly from all existing workflows.
- Interoperability: 600% faster spatial data transmission to other teams through full data interoperability
- Scalability: 100% scalable spatial data ingestion and management pipeline for existing and new 2D/3D spatial data vendors
Conclusion
In the ever-evolving landscape of the insurance industry, where the stakes are higher than ever, embracing automation in the ingestion of spatial and climate data into existing data warehouses isn’t just an option, it’s a necessity. The challenges associated with manual data ingestion are not merely resource-draining, they pose a serious risk to an insurer’s ability to navigate the turbulent waters of our rapidly changing environment. By embracing automation, the insurance industry can turn the challenge of climate risk into an opportunity for a more resilient, efficient and sustainable future.
Would you like to know more about how Ellipsis Drive can improve your bottom line at a 8X to 26X ROI? Book a free demo with our Head of Sales for a detailed walkthrough on how Ellipsis Drive can fit your business needs and help you master your risk!
Liked what you read?
Subscribe to our monthly newsletter to receive the latest blogs, news and updates.
Take the Ellipsis Drive tour
in less than 2 minutes'
- A step-by-step guide on how to activate your geospatial data
- Become familiar with our user-friendly interface & design
- View your data integration options
Related Articles
Tackling Land Subsidence with Ellipsis Map Engine
Pipeline infrastructure is central to the Oil & Gas industry, enabling the safe and efficient transport of resources across long distances. But this infrastructure faces constant threats from natural
5 min read
Opportunities for the Insurance Industry (2023)
What is the difference between a challenge and an opportunity? It could be argued that they are one and the same. That a challenge is just an opportunity in disguise. In need of someone to innovate a
7 min read
How to Build a Spatial Data Catalog
Let’s start off with a hypothetical example. Say you are the manager of an Amazon warehouse and you receive an order to ship a book (maybe The Salt Path by Raynor Winn). But none of the million thing
5 min read